As your enterprise grows, so do its sources of information. An inability to recognize and correlate diverse streams of information is often why successful companies slide. These streams, which often include structured and unstructured data – like M2M/IoT chatter, SM feeds, images – seldom amalgamate into a single, universally accessible body of data, preventing a consolidated view.
Stemming from the aspiration of new age enterprises to stay relevant in the face of increased size and complexity of data, and to take advantage of the new opportunities that big data offers, data lakes are fast becoming the mainstay of enterprise data initiatives.

An enterprise data lake (EDL) is a single repository of all enterprise data in its raw format which can be transformed to meet a range of requirements, from visualization to machine learning. It can store unlimited types of data, which can be refined to yield better insights as your business and worldview grows. Thus, data lakes enable you to derive far greater value from data.
As important as data lakes are to the present and future of business, it is required to weigh in at least the below seven factors before deciding to build one for your enterprise.
1. A data lake removes all restrictions to data flow
There is one clear axiom that precedes the decision on data lakes: every type of data is a vital asset that your business needs, or will need, to survive. In other words, you cannot afford to pick and choose the type of data that you will store – or ignore. The plugs must be pulled out from every stream of data, allowing it to flow unhindered into the larger reservoir – which is your enterprise data lake.
Think of each data stream as a tributary that culminates into the data lake. The data lake collects all your enterprise data, including unstructured data, and stores it for later processing in varied scenarios. It is murkier but adapts better to changing or unknown business requirements – as opposed to a data warehouse, which is tidier but is confined to known requirements.
2. A data lake is not (just) a database
A data lake is a repository of data that is both structured – or in relational data base table form – and unstructured. A database conforms to a fixed structure, following the schema-on-write (or extract-transform-load) method, while a data lake conforms to schema-on-read (or extract-load-transform) method. That is, a data lake can hold data that can be transformed to a database structure when needed, along with other forms of data. In short, a data lake is not simply a data base – which could be just one of the many instances of the data lake.
3. A data lake is not a substitute for a data warehouse
A data warehouse is a repository of processed data suitable for use cases that are known ahead of time. It works great when you need the data to be in a specific format for visualization and presentation directly by business users.
A data lake, on the other hand, is a body of unprocessed data in its natural state. It is not suitable for applications where data must be readily available in a specific format. Being raw, it is inaccessible to all but data experts. As a repository for all organizational data, structured and unstructured, the data lake, however, can generate far more valuable insights over time than a data warehouse.
A data lake would be ideal in the healthcare industry for storing patient records, which include hand-written prescriptions, images, and scans in raw format, alongside structured data from hospital management system.
On the other hand, a data warehouse is better suited to the Banking industry as it enables easier access to information by the end-users than a data lake.
In conclusion, you probably need both – a data warehouse and a data lake. A data lake enables you to harness big data and gain from the flexibility and raw power of granular, unprocessed data. A data warehouse is useful to business users for ease of analytics and research.
4. Strong Business-IT integration is vital to successful data lake evolution
Building a data lake is increasingly about the Business and IT teams working together to realize the enterprise’s vision. Intense planning around the strategy, tasks, modules, KPIs, and implementation phases is as integral to the build-up as the deployment itself.
Every enterprise crafts its own data lake story. However, the following aspects cut across narratives.
- Defining the overall data lake architecture and the key technologies that comprise it
- Identifying the sources of data and ingestion requirements for each source
- Establishing rules for retention and archival
- Deciding on Cloud-based or on-premise solution
- Constructing the data organization for optimum retrieval
- Specifying the data security and encryption requirements
- Setting up data governance mechanism
If you find the task of building your data lake somewhat outside your sphere of competence, that’s okay. The good news is that help is at hand. There are several organizations that offer customized services, and pre-built technology stacks are available that make the task less daunting. But in any case, the reins must firmly be in your hands.
5. A data lake is a modular entity built progressively on a big data platform like Hadoop
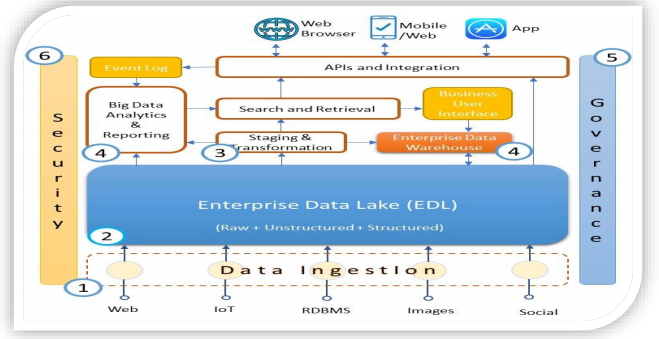 The data lake architecture involves selecting and integrating modules from different technology providers. There is no best-of-suite solution. Further, it is unwise to wait for the end-state architecture to be in place before launch. It is best to start small and scale up the solution with your needs.
The data lake architecture involves selecting and integrating modules from different technology providers. There is no best-of-suite solution. Further, it is unwise to wait for the end-state architecture to be in place before launch. It is best to start small and scale up the solution with your needs.
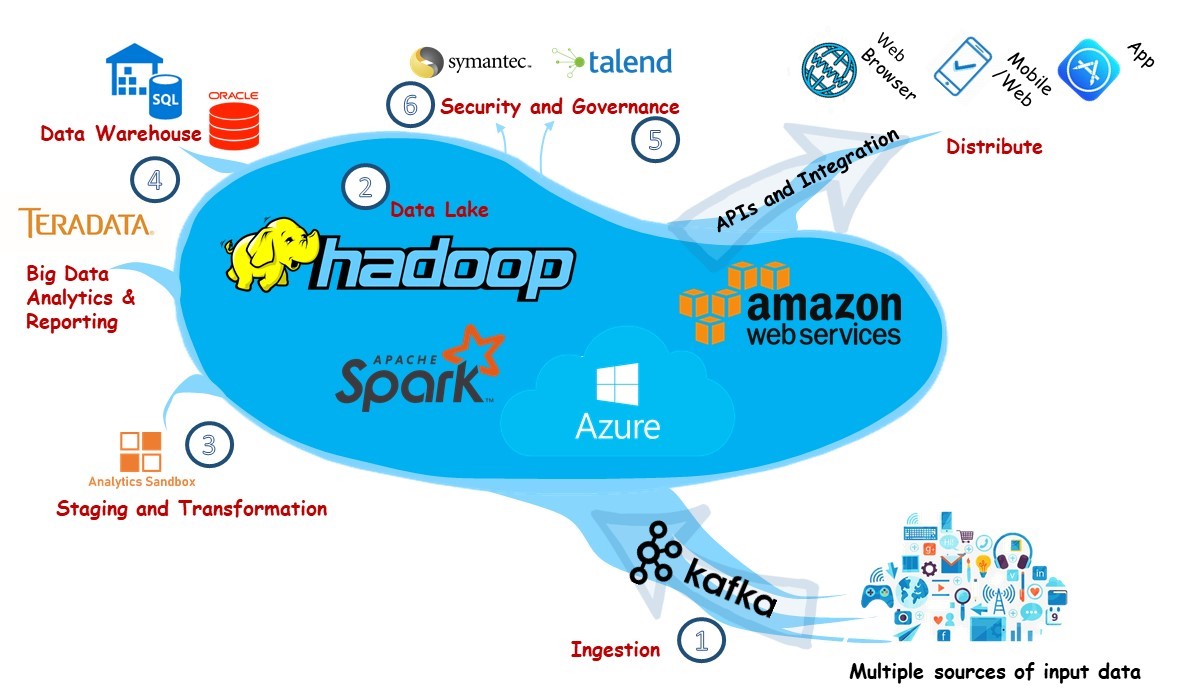
The typical elements surrounding a data lake are shown in this simplified view of a possible EDL architecture. The core technology, of course, is the storage, as a data lake when stripped of all its fineries, is just a vast repository of data. Here are representative technology components that could be part of this architecture.
Data Ingestion Tools: Data is moved to the lake using Sqoop, Flume, and Kafka, with custom coding in Java or Scala.
Enterprise Data Lake Repository: Hadoop distributed file system (HDFS) is the platform for data lakes, supported by cloud object stores like AWS/S3 or Microsoft Azure for economical storage of large files.
Staging and Transformation Module: The EDL architecture uses Analytics Sandbox for transforming and staging.
Enterprise Data Warehouse and Analytics: The EDL architecture supports analytics and visualization using Teradata, Oracle, AWS, or Cloudera warehousing solution.
Governance Framework: For rendering trusted data, the EDL may employ Talend, Informatica, and Modak governance framework.
Security Layer: Symantec, Hortonworks, and Imperva encryption and multi-factor security solutions assure full and continuous protection of EDL data
6. You can build an EDL architecture with Open Source technology
Basic EDL architectures can be built with open source technology comprising Hadoop and Apache Spark. However, a pure open source implementation may be fragmentary and complex to implement. Often, a hybrid of open source and licensed modules is the most optimal for real-world EDL implementations.
7. The data lake has its monsters too
Remember, data lakes store raw data which has not yet been processed for a purpose. Thus, data lakes require a much higher storage capacity than, say, a data warehouse. Further, there is no contextual metadata, processes, or standards associated with raw data. Therefore, in the absence of strict governance and quality control, a data lake may turn into a data swamp – or a body of ungoverned, inaccessible, and useless data.
The data lake may not lend itself to any rule-based filtration or organization. This makes the storage inefficient and unruly. A focused data management strategy is required to manage these fallouts.
Navigating a data lake requires experts, like data scientists, to understand and translate the unprocessed data for business use. However, increasingly sophisticated data preparation tools are now available that enable self-service access to the data lake repository.
A data lake is not simply a piece of the IT infrastructure. It is a business calling and, therefore, requires strong alignment between business and IT. Siloed thinking is often the main reason for failed data lake initiatives.
Due to lack of structure, the data in a data lake can be quickly and easily manipulated, which calls for stricter access controls.
A data lake is not a magic bullet by itself. It is a part of a much larger, and still evolving, ecosystem of interdependent systems which collectively boost the present and future business value of the enterprise.
For most companies, the core focus is not on building data lakes but on running their business profitably. It is, therefore, always good to have a trusted partner on your side who understands not just data lakes, but your business as well. But more importantly, the business and IT leaders of the enterprise must drive it as a shared mission with the flexibility to start small, target some quick wins, and build the team’s confidence for scaling up as your business grows.